Retroconversion
What is retroconversion?
Retroconversion is the digitisation of paper catalogues.
An important task of archives and archivists is creating good catalogues for their collections. A catalogued collection is transparent to both archive staff and visitors, and you can only use a document if you know it exists. Worcestershire Archives has been cataloguing its collections since it came into being in 1947. Initially, we catalogued on paper, but we now use a digital cataloguing database called Axiell CALM.
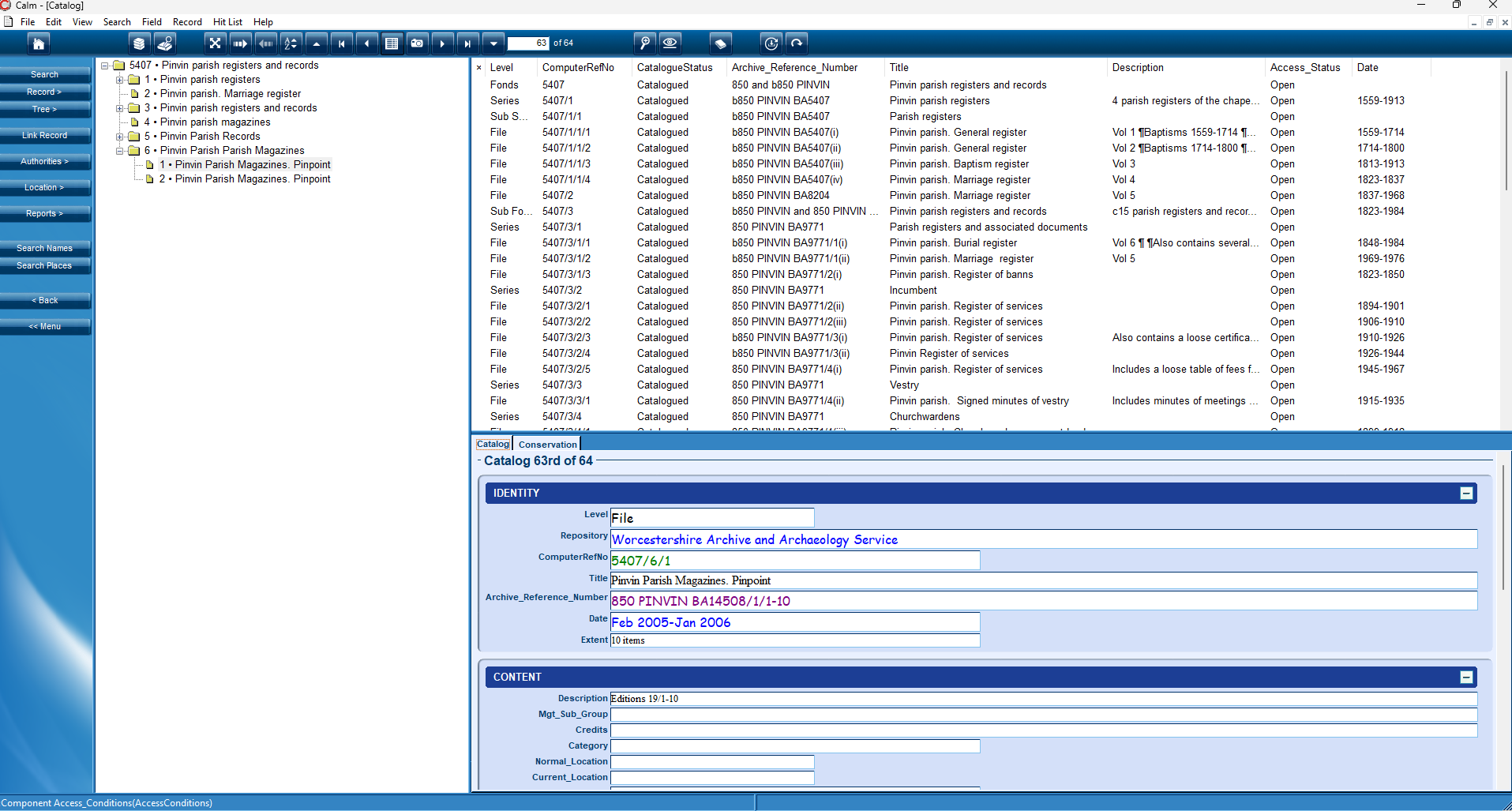
A catalogue viewed in CALM, our digital catalogue. This catalogue, BA5407, is currently available online!
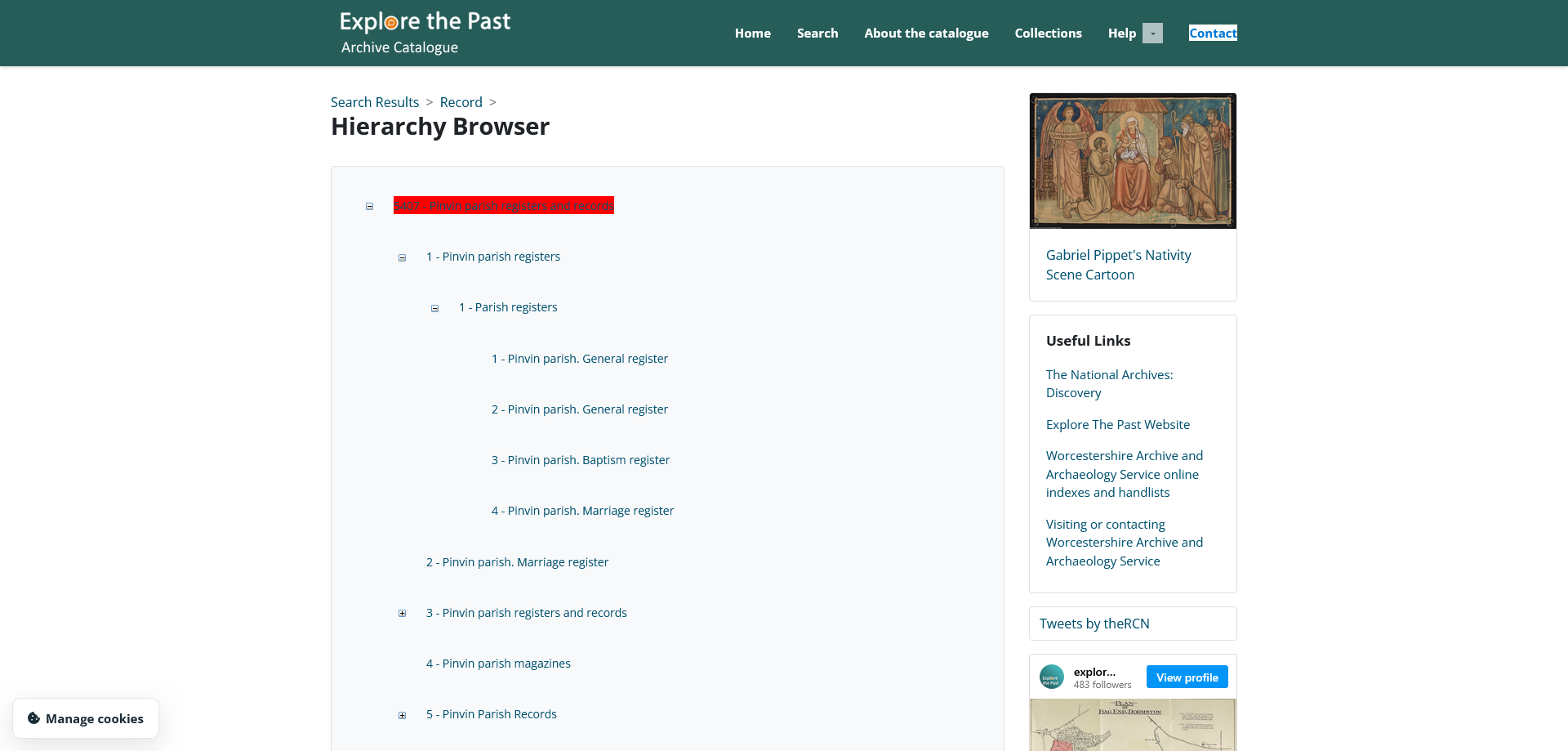
The same catalogue, BA5407, in CALMview, our online catalogue!
Digital cataloguing is part of archives best practice today. Digital catalogues are easily searchable, by reference number and keyword, and are more accessible, as they can be accessed remotely through an online portal. Today, around 15% of our collections are available through CALM. The remainder of our collections are only catalogued on paper.
Anyone who wants to look through one of our paper catalogues would have to either travel to the Hive in person or pay a team member to carry out a search, and that supposes that a user would realise we hold a collection in the first place. Imagine if you saw we had an online catalogue view, and couldn’t find what you were looking for. You might conclude we didn’t hold relevant records, when we did, and the information simply hadn’t been added to CALM.
We catalogue newly acquired collections straight onto CALM, and have already done some retroconversion. We’ve never really been able to focus on it, though, and so haven’t made the progress we want, and which other county archives have. Therefore, we’ve identified retroconversion as a top priority for 2025-2027. We hope to meet a target of having around 70% of our catalogues available digitally and online during 2027.
What are we doing?
At present, we’re manually entering accession entries into CALM. These are basic outlines of a collection created when that collection is deposited with us. Simultaneously, we’re scanning catalogue pages. We’re going to use OCR software to extract text from those scanned pages, which can then be ingested into CALM en masse. We can then associate the OCR text with the accession entry in CALM to make a catalogue. This should be considerably quicker than manual entry, and we’re also currently exploring the use of AI tools to speed up this process.
As of May, we have over 90% of catalogue pages scanned.
What will be posted under this project?
Going back over our catalogues means that we’ve rediscovered some interesting collections. We’ll be posting blogs about some of those here. Additionally, we hope to keep you updated about our progress more generally.
For further updates, find us on Facebook and Instagram.
If you have any questions, please get in touch at Contact Us.